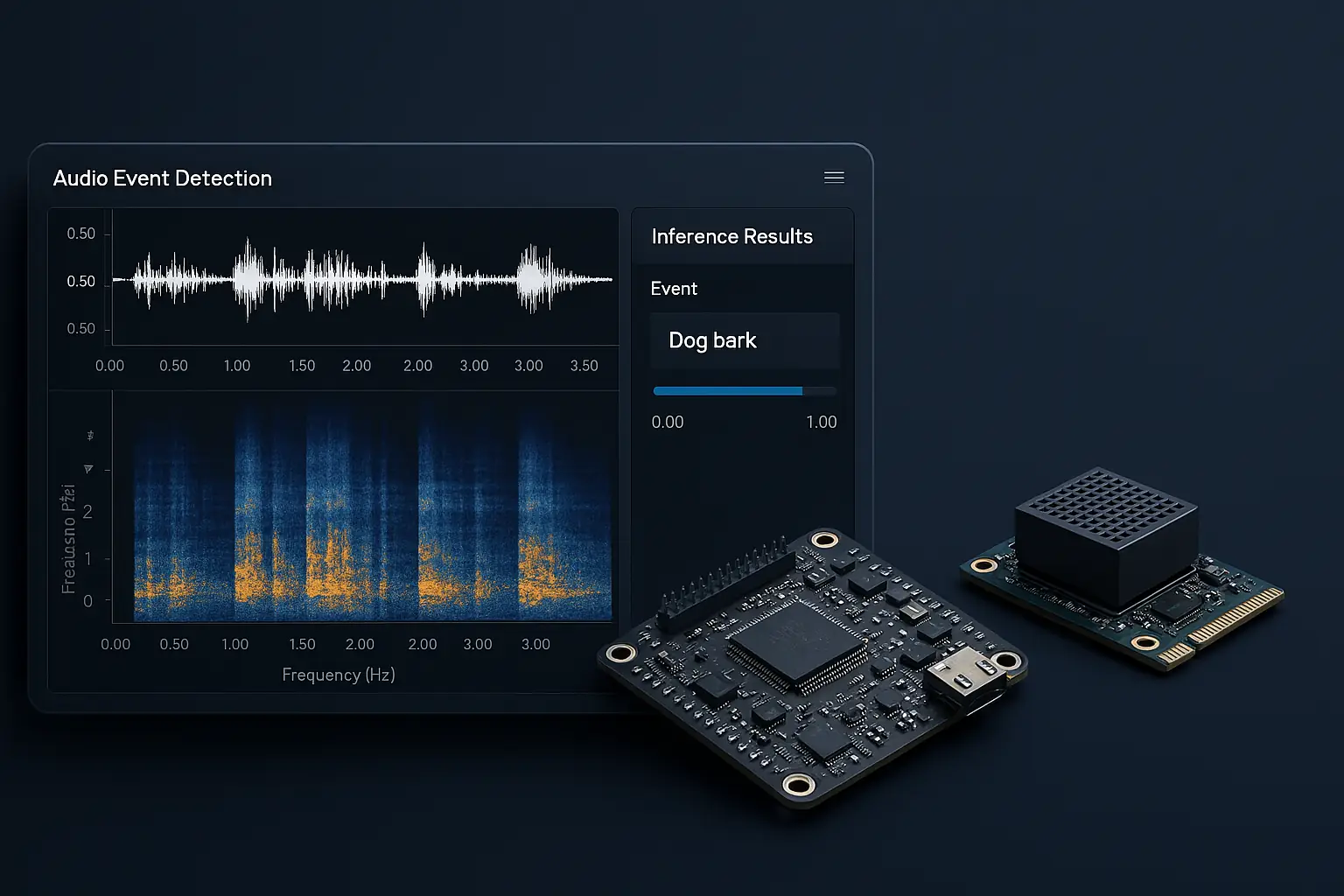
Contesto
La soluzione nasce dall'esigenza di rilevare eventi sonori direttamente su un microcontrollore, senza dipendere da connettività di rete, server remoti o sistemi operativi. In molti prodotti IoT il riconoscimento audio viene delegato al cloud, introducendo latenza, costi operativi e dipendenze difficili da gestire in produzione.
L'obiettivo è portare l'intelligenza artificiale audio direttamente sul device: un modello addestrato in Python che viene esportato come codice C statico, compilato insieme al firmware e capace di girare su bare-metal senza malloc, filesystem o RTOS.
L'approccio privilegia la semplicità dell'integrazione e la prevedibilità del comportamento a runtime. Il modello non è un componente opaco: è codice C leggibile, verificabile e ricompilabile ogni volta che il dataset viene aggiornato.

Esigenze progettuali
Il sistema deve rispondere a vincoli tipici di un contesto embedded professionale, dove le risorse sono limitate e l'affidabilità è un requisito non negoziabile.
Le principali esigenze progettuali includono la possibilità di classificare suoni in tempo reale su un singolo core, l'assenza di dipendenze da librerie C esterne, la riproducibilità del processo di training e la possibilità di rigenerare il modello dopo ogni nuovo dataset senza modificare il firmware manualmente.
Un approccio basato su librerie ML precompilate per embedded è spesso difficile da portare su architetture diverse. La priorità è quindi generare codice C portatile, compatibile con qualsiasi toolchain — GCC, Clang, IAR, ARMCC — e integrabile in qualsiasi progetto senza dipendenze aggiuntive.
Struttura tecnica
La soluzione è organizzata in due layer distinti: un layer Python per il training e l'export, e un layer C per l'inferenza su microcontrollore. I due livelli comunicano attraverso i file generati dallo script di export, che contengono l'intero modello serializzato come array statici.
Il layer Python si occupa di raccogliere campioni audio, estrarre le feature con
finestre scorrevoli da 300ms e addestrare un RandomForestClassifier con
normalizzazione tramite StandardScaler. Lo script export_c_model.py
serializza poi ogni albero della foresta — nodi, soglie, indici di feature, valori foglia —
e i parametri dello scaler direttamente in header e sorgenti C.
Il layer C espone una API minimale: tre funzioni pubbliche che ricevono il vettore di feature da 36 float e restituiscono la classe predetta, le probabilità per classe e il nome stringa dell'etichetta. Non è richiesta alcuna inizializzazione di heap o strutture dinamiche.
Feature extraction — 36 descrittori per finestra
Per ogni finestra da 300ms il frontend audio calcola sei famiglie di descrittori, di cui vengono estratti media e deviazione standard. Il vettore da 36 valori risultante è identico sia in fase di training che in fase di inferenza, garantendo coerenza tra modello Python e comportamento su MCU.
- MFCC (26 feature): 13 Mel-Frequency Cepstral Coefficients, media e std. Catturano timbrica e contenuto spettrale in modo compatto.
- RMS (2 feature): energia del segnale, utile per distinguere suoni impulsivi dal rumore di fondo.
- ZCR (2 feature): zero crossing rate, indice di percussività e presenza di componenti ad alta frequenza.
- Spectral centroid, rolloff, bandwidth (6 feature): caratterizzano la distribuzione dell'energia nelle bande di frequenza e la "brillantezza" del suono.

Modalità operative
Il sistema supporta due configurazioni. In modalità multiclasse il modello
distingue tra tutte le etichette presenti nel dataset — ad esempio clap,
double_clap, knock, whistle, background.
In modalità detect/no-detect è possibile indicare una o più etichette
positive e collassare tutte le altre in una singola classe negativa, ideale per trigger
o rilevatori di eventi specifici con soglia configurabile a runtime.
Architettura orientata alla portabilità
Il codice C generato non dipende dall'architettura target. Lo stesso modello compilato su un ESP32 può essere ricompilato su un STM32, un nRF52 o qualsiasi altro MCU supportato dalla toolchain. La sola parte da adattare è il frontend DSP, che calcola le feature audio usando la libreria disponibile sul target — CMSIS-DSP, ESP-DSP o un'implementazione custom.
Metodologia di sviluppo
Lo sviluppo segue un ciclo iterativo che parte dalla raccolta dei campioni audio e arriva all'integrazione nel firmware, con ogni fase verificabile in modo indipendente. Il processo è ripetibile: aggiornare il dataset e rigenerare il modello richiede l'esecuzione di due comandi.
La raccolta dati avviene direttamente da microfono tramite CLI, con durata e etichetta configurabili per ogni sessione di registrazione. I campioni vengono salvati in cartelle separate per classe e usati in training con finestramento automatico per file lunghi.
# Registrazione campioni
python main.py record --label knock --seconds 4
python main.py record --label background --seconds 6
# Training e validazione
python main.py train
# Export C per il firmware
python tools/export_c_model.py \
--model models/sound_model.joblib \
--out-dir embedded
La qualità del modello è direttamente proporzionale alla varietà dei campioni.
Si raccomanda di registrare in ambienti e a distanze diverse, con almeno 30 campioni
per classe (ottimale 80+) e una classe background rappresentativa delle
condizioni operative reali, per ridurre i falsi positivi.
L'integrazione nel firmware richiede di aggiungere i file generati al progetto, implementare il calcolo delle feature nel frontend DSP e richiamare le API di inferenza nel loop di acquisizione audio.
Output
Il risultato è un set di file C pronti per essere inclusi in qualsiasi progetto firmware, accompagnati da un'API documentata e da un template di integrazione.
- File
sound_model.hesound_model.ccon il modello serializzato - File
audio_frontend.heaudio_frontend.ccon il template di feature extraction - API C stabile: predict, predict_proba, class_name
- Script Python per training, validazione e rigenerazione del modello
- Pipeline CLI completa per raccolta dati, training e inferenza su file
Integrazione nel firmware
Il contratto tra firmware e modello è minimale e stabile. L'unica funzione da
implementare sul target è af_compute_frame_descriptors(), che calcola
i descrittori audio frame per frame usando la libreria DSP del target. Il template
gestisce automaticamente finestramento, accumulo e costruzione del vettore mean/std.
/* Esempio di loop di inferenza su MCU */
 float feats[AF_FEATURES_COUNT];
af_extract_features(&g_af, pcm_q15, feats);
float probs[SOUND_MODEL_NUM_CLASSES];
sound_model_predict_proba(feats, probs);
/* Soglia configurabile a runtime */
if (probs[detect_idx] >= 0.60f) {
/* evento rilevato */
}
float feats[AF_FEATURES_COUNT];
af_extract_features(&g_af, pcm_q15, feats);
float probs[SOUND_MODEL_NUM_CLASSES];
sound_model_predict_proba(feats, probs);
/* Soglia configurabile a runtime */
if (probs[detect_idx] >= 0.60f) {
/* evento rilevato */
}Casi d'uso verificati
La soluzione è applicabile a qualsiasi scenario in cui sia necessario rilevare un evento acustico in modo locale, con reazione immediata e consumo energetico controllato: controllo gestuale senza contatto, rilevamento anomalie su macchinari, wake-word custom per attivare il sistema da uno stato di basso consumo.
Applicazione del metodo
L'approccio utilizzato per questa soluzione non è legato a un singolo tipo di suono o a una specifica piattaforma hardware. La stessa pipeline — raccolta, training, export C — può essere applicata a qualsiasi problema di classificazione audio su embedded, variando solo le classi del dataset e il frontend DSP del target.
Il modello può essere rigenerato ogni volta che il contesto operativo cambia: nuovi ambienti, nuove varianti del suono da rilevare, nuove classi da distinguere. Il firmware non richiede modifiche strutturali — basta ricompilare con i nuovi file C.
In questo modo è possibile realizzare soluzioni di riconoscimento audio su misura, pronte per crescere insieme al prodotto e adattarsi a requisiti che evolvono nel tempo.

