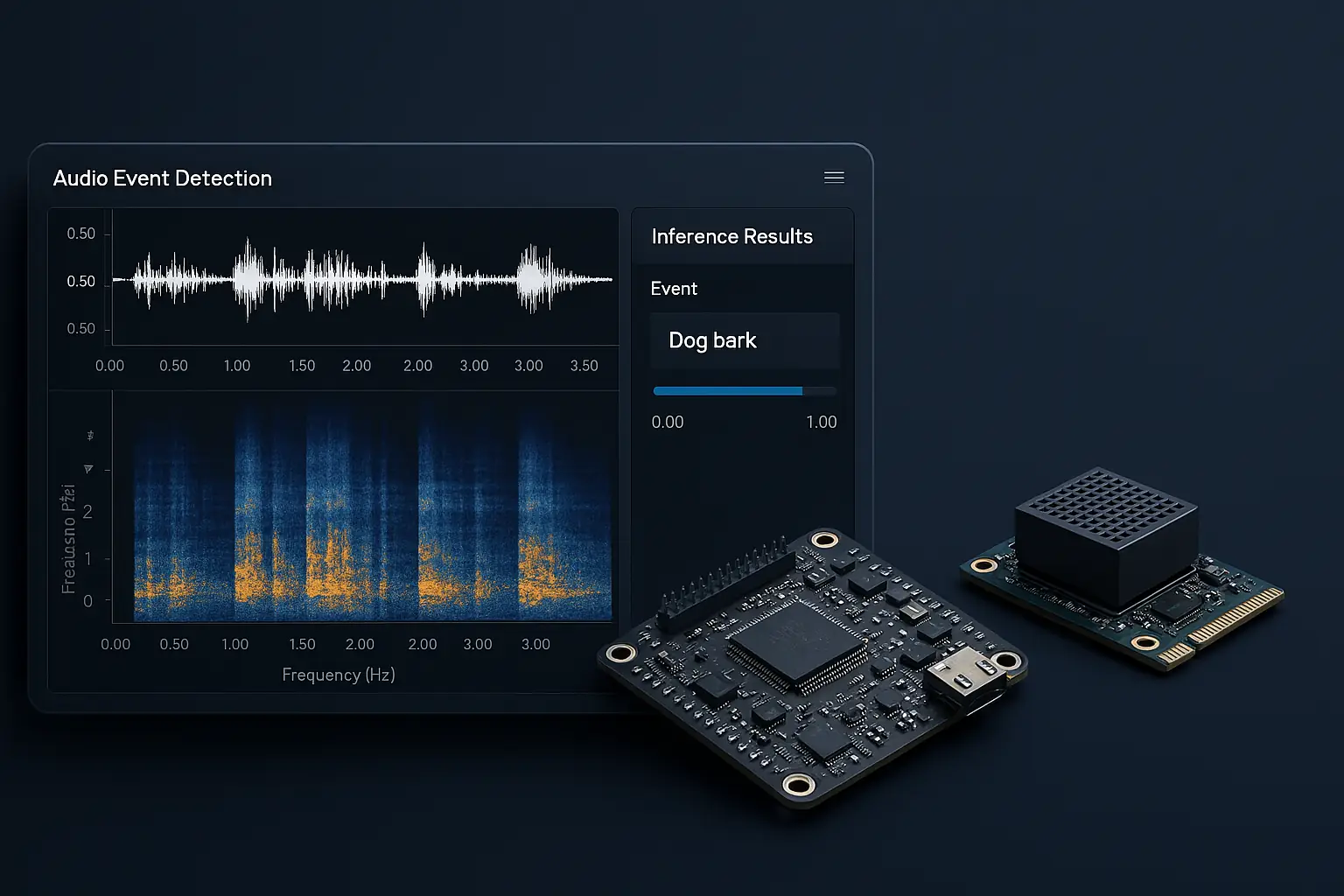
Context
The solution was born from the need to detect sound events directly on a microcontroller, without depending on network connectivity, remote servers or systems operational. In many IoT products, audio recognition is delegated to the cloud, introducing latency, operational costs and dependencies that are difficult to manage in production.
The goal is to bring audio artificial intelligence directly to the device: a model trained in Python which is exported as static C code, compiled alongside the firmware and capable of running on bare-metal without malloc, filesystem or RTOS.
The approach favors the simplicity of integration and the predictability of runtime behavior. The model is not an opaque component: it is readable C code, verifiable and recompilable every time the dataset is updated.

Design needs
The system must respond to constraints typical of a professional embedded context, where resources are limited and reliability is a non-negotiable requirement.
Key design needs include the ability to classify sounds into real time on a single core, the absence of dependencies on external C libraries, the reproducibility of the training process and the possibility of regenerating the model after each new dataset without changing the firmware manually.
An approach based on precompiled ML libraries for embedded is often difficult to achieve bring to different architectures. The priority is therefore to generate portable C code, compatible with any toolchain — GCC, Clang, IAR, ARMCC — and embeddable into any project without additional dependencies.
Technical structure
The solution is organized into two distinct layers: a Python layer for training and export, and a C layer for microcontroller inference. The two levels communicate through the files generated by the export script, which contain the entire model serialized as static arrays.
The Python layer takes care of collecting audio samples, extracting features with
300ms sliding windows and train a RandomForestClassifier with
normalization via StandardScaler. The script export_c_model.py
then serializes each tree in the forest — nodes, thresholds, feature indices, leaf values —
and scaler parameters directly in headers and C sources.
Layer C exposes a minimal API: three public functions that receive the vector of 36 float features and return the predicted class,probabilities per class and the string name of the label. No heap initialization is required or dynamic structures.
Feature extraction — 36 descriptors per window
For each 300ms window the audio frontend calculates six families of descriptors, of which the mean and standard deviation are extracted. The vector with 36 values resulting is identical both in the training phase and in the inference phase, guaranteeing consistency between Python model and behavior on MCU.
- MFCC (26 features): 13 Mel-Frequency Cepstral Coefficients, mean and std. They capture timbre and spectral content compactly.
- RMS (2 features): signal energy, useful for distinguishing impulsive sounds from background noise.
- ZCR (2 features): zero crossing rate, percussiveness index and presence of high frequency components.
- Spectral centroid, rolloff, bandwidth (6 features): they characterize the distribution of energy in the frequency bands and the "brilliance" of the sound.

Operating modes
The system supports two configurations. In mode multiclass the model
distinguishes between all labels in the dataset — for example clap,
double_clap, knock, whistle, background.
In mode detect/no-detect it is possible to indicate one or more labels
positive and collapse all the others into a single negative class, ideal for triggers
or specific event detectors with threshold configurable at runtime.
Portability-oriented architecture
The generated C code does not depend on the target architecture. The same filled out template on an ESP32 can be recompiled on an STM32, an nRF52 or any other MCU supported by the toolchain. The only part that needs to be adapted is the DSP frontend, which does the computing audio features using the library available on the target — CMSIS-DSP, ESP-DSP or a custom implementation.
Development methodology
Development follows an iterative cycle that starts from the collection of audio samples and arrives at integration into the firmware, with each step independently verifiable. The process is repeatable: updating the dataset and regenerating the model requires executing two commands.
Data collection takes place directly from the microphone via CLI, with duration and label configurable for each recording session. Samples are saved in folders separated by class and used in training with automatic windowing for long files.
# Registrazione campioni
python main.py record --label knock --seconds 4
python main.py record --label background --seconds 6
# Training e validazione
python main.py train
# Export C per il firmware
python tools/export_c_model.py \
--model models/sound_model.joblib \
--out-dir embedded
The quality of the model is directly proportional to the variety of the samples.
It is recommended to record in different environments and at different distances, with at least 30 samples
per class (optimal 80+) and one class background representative of
real operating conditions, to reduce false positives.
Integration into firmware requires adding the generated files to the project, implement feature calculation in the DSP frontend and call the APIs inference in the audio capture loop.
Outputs
The result is a set of C files ready to be included in any project firmware, accompanied by a documented API and an integration template.
- File
sound_model.hAndsound_model.cwith the serialized model - File
audio_frontend.hAndaudio_frontend.cwith the feature extraction template - Stable C API: predict, predict_proba, class_name
- Python script for model training, validation and regeneration
- Comprehensive CLI pipeline for data collection, training, and file inference
Firmware integration
The contract between firmware and model is minimal and stable. The only function from
implement on the target is af_compute_frame_descriptors(), which calculates
audio descriptors frame by frame using the target's DSP library. The template
automatically manages windowing, accumulation and construction of the mean/std vector.
/* Esempio di loop di inferenza su MCU */
 float feats[AF_FEATURES_COUNT];
af_extract_features(&g_af, pcm_q15, feats);
float probs[SOUND_MODEL_NUM_CLASSES];
sound_model_predict_proba(feats, probs);
/* Soglia configurabile a runtime */
if (probs[detect_idx] >= 0.60f) {
/* evento rilevato */
}
float feats[AF_FEATURES_COUNT];
af_extract_features(&g_af, pcm_q15, feats);
float probs[SOUND_MODEL_NUM_CLASSES];
sound_model_predict_proba(feats, probs);
/* Soglia configurabile a runtime */
if (probs[detect_idx] >= 0.60f) {
/* evento rilevato */
}Verified use cases
The solution is applicable to any scenario where you need to detect a acoustic event locally, with immediate reaction and controlled energy consumption: non-contact gesture control, anomaly detection on machinery, custom wake-word to activate the system from a low power state.
Application of the method
The approach used for this solution is not tied to a single type of sound or to a specific hardware platform. The same pipeline — collection, training, export C — can be applied to any embedded audio classification problem, varying only the classes of the dataset and the DSP frontend of the target.
The model can be regenerated whenever the operating context changes: new environments, new variations of sound to detect, new classes to distinguish. The firmware requires no structural changes — just recompile with new C files.
In this way it is possible to create tailor-made audio recognition solutions, ready to grow together with the product and adapt to requirements that evolve over time.

